Wer heute ein neues Auto kauft, kommt um Künstliche Intelligenz (KI) nicht herum, die Künstliche Intelligenz ist überall. In Smart Home Geräten in PCs, Handys, Laptops und in Putz-Roboters. Fast jeder Haushalt hat mindestens eine Künstliche Intelligenz, meist aber nur unbewusst. Google-Chef, Sundar Pichai hat 2018 auf einer Veranstaltung in San Francisco gesagt „künstliche Intelligenz ist eines der wichtigsten Dinge, an denen Menschen arbeiten. Ihre Bedeutung ist grundlegend der als Elektrizität oder das Feuer“.[1]
Ich habe dieses Thema gewählt, da ich denke, dass die Künstliche Intelligenz zunehmend sehr wichtig für unsere Gesellschaft wird, und mir deshalb die Frage gestellt habe, ob überhaupt eine Künstliche Intelligenz schlauer werden kann als der Mensch. Und da manche Leute Angst vor der Künstlichen Intelligenz haben, weil sie denken, dass die Künstliche Intelligenz die Menschen auslöschen könnte. In dieser Arbeit will ich außerdem erklären, wie eine Künstliche Intelligenz funktioniert, so dass man versteht, warum ich zu meinem Ergebnis gekommen bin.
Nun Was bedeutet „künstliche Intelligenz“ (eng. „Artificial Intelligence“) eigentlich? Der Begriff Künstliche Intelligenz ist schwierig zu definieren, da es laut Wikipedia „an einer genauen Definition von ‚Intelligenz‘ mangelt“.[2] Das hat vielerlei Ursachen. Die größte Ursache ist, dass sich Forscher nicht einig sind, wann jemand als intelligent gilt. Da jeder Mensch seine eigene Vorstellung davon hat, was Intelligenz bedeutet und welche Fähigkeiten als intelligent betrachtet werden, ist es schwierig, eine einheitliche Definition zu finden. Zum Beispiel kann jemand Intelligenz mit einer hervorragenden Fähigkeit im Rechnen assoziieren, während eine andere Person Intelligenz mit einer exzellenten Kommunikationsfähigkeit in Beziehung setzt. Ein versuch, die Intelligenz zu definieren, ist laut dem Buch „Allgemeinbildung Künstliche Intelligenz Risiko und Chance“
„[...] das Anwenden und Schaffen eines inneren Modells beziehungsweise einer inneren Funktion, um auf Reize der Umgebung adäquat (angemessen) zu reagieren und bei beobachteten Fehlern das eigene Modell über die Umgebung beziehungsweise die Übertragungsfunktion selbständig so anzupassen, dass beim nächsten Mal eine adäquate Reaktion erfolgen kann“.[3]
Also ist eine KI laut dem gleichen Buch „[...] Versuch, rationale bzw. kognitive menschliche Intelligenz auf (technischen) Maschinen zu simulieren.“ [3] vereinfacht gesagt ist es der Versuch, dass ein Computer dank Programmierung die Welt mit allen Sinnen erfährt und mit ihr interagiert wie der Mensch. Und daraus ein mindestens gleich gutes Verständnis der Welt durch selbständiges Lernen ableitet. Heißt die KI muss die Welt verstehen, daraus lernen und mit ihr adäquat interagieren.
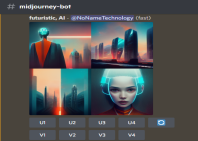
Die KI verwendet man z.B., um dem Arzt bei der Diagnose, Überwachung und Behandlung von Patienten sowie der Verwaltung von medizinischen Aufzeichnungen zu helfen. Sie kann auch bei der Entwicklung neuer Medikamente oder Impfstoffe sowie bei der Erforschung von Virusübertragungen unterstützen. Die KI wird in China auch zur Überwachung von Personen eingesetzt. Mit Hilfe von Überwachungskameras und KI-Systemen kann China jede Person filmen und ihr Verhalten beurteilen. Die KI kann dann anhand dieses Verhaltens Punkte vergeben und feststellen, ob das Verhalten gut oder schlecht ist. Die KI hilft aber nicht nur bei der Medizin oder dem Land, sondern auch im alltäglichen Leben, z.B. wenn man bei Google Lens ein Objekt fotografiert, sucht die KI das passende Ergebnis aus der Datenbank, oder wenn man bei Google Fotos „Katze“ eintippt, sucht die KI das passende Foto aus dem Foto Album. Dank von Google entwickelte KI namens BERT (Bidirectional Encoder Representations from Transformers) kann Google nun seit 2019 viel präziser seine Suchanfragen beantworten, da Google durch BERT genauer weiß, was der Benutzer im Internet finden möchte.[4] Auch Streaming-Dienste wie YouTube, Spotify, Netflix oder Amazon Prime Video verwenden eine KI. Denn durch die KI können die Plattformen mit gesammelten Daten Interessantere Inhalte für die Nutzer anzeigen. Mit einer KI kann man aber auch Bilder aus Texten Generieren, zum Beispiel mit der KI „Midjourney“ welches am 13.07.2022 veröffentlicht wurde, und in den Medien für große Aufmerksamkeit gesorgt hat. Auf der Abbildung 1 sieht man ein Bild welches Midjourney aus den wörtern „futuristic“ und „AI“ erzeugt hat. Eine weitere KI die 2022 für große Aufmerksamkeit gesorgt hat ist die KI „Chat-GPT“ welches mit einer Person kommunizieren, ein Programm Code schreiben oder Fehler Lösen, Hausaufgaben lösen oder Gedichte schreiben und analysieren kann. Hier kann man weitere Beispiele von Midjourney und Chat-GPT sich anschauen: https://nonametechnology.netlify.app/ki
Der Begriff Künstliche Intelligenz ist im Sommer 1956 bei einer Konferenz am Dartmouth College im US-Bundesstaat New Hampshire entstanden. Die Wissenschaftler sind der Ansicht, dass die Aspekte des Lernens sowie die Merkmale der menschlichen Intelligenz auf Maschinen simuliert werden können. Dabei schlägte der Programmierer John McCarthy den Begriff „Künstliche Intelligenz“ vor.[5] “Einen Durchbruch für Künstliche Intelligenz prognostizierte McCarthy in‚fünf bis 500 Jahren‘“.[6] Seitdem hat sich der Begriff „Künstliche Intelligenz“ zu einem weit verbreiteten Begriff entwickelt, der in vielen Bereichen der Informatik und Technologie verwendet wird.
Es gibt bei einer KI zwei verschiedene Arten, eine schwache und eine starke KI. Die Schwache KI ist die die zurzeit in allen KI´s verwendet wird, da eine Realisierung einer starken KI noch nicht in greifbarer Nähe liegt.
Aber was ist der Unterschied zwischen einer schwachen und starken KI, und warum ist eine starke KI noch nicht realisierbar?
Eine schwache KI ist für ein bestimmtes Aufgabenfeld begrenzt und dafür trainiert (z.B. Erkennung von Gesichtern auf Fotos), weswegen es keine anderen Probleme lösen kann. Auf der Website THWS (Technische Hochschule Würzburg-Schweinfurt) wird die schwache KI sehr gut beschrieben:
„Die schwache KI (auch als methodische KI bezeichnet) besitzt keine Kreativität und keine expliziten Fähigkeiten selbstständig im universellen Sinne zu lernen. Ihre Lernfähigkeiten sind zumeist auf das Trainieren von Erkennungsmustern (Machine Learning) oder das Abgleichen und Durchsuchen von großen Datenmengen reduziert. Mit ihr Können klar definierte Aufgaben mit einer festgelegten Methodik bewältigt werden, um komplexere, aber wiederkehrende und genau spezifizierte Probleme zu lösen. Die besonderen Vorzüge der schwachen KI liegen in der Automatisierung und im Controlling von Prozessen, aber auch der Spracherkennung und verarbeitung. Zum Beispiel: Text- und Bilderkennung, Spracherkennung, Übersetzung von Texten, Navigationssysteme etc.
Auch digitale Assistenzsysteme wie Alexa, Siri und Google Assistent gehören zur Kategorie der schwachen KI.“ [7]
Eine starke KI ist, die selber Emotionen, Gefühle und künstliches Bewusstsein entwickelt. Auch hier hat THWS eine gute Beschreibung für die starke KI:
„Die Zielsetzung des Konzeptes der starken KI ist es, dass natürliche und künstliche Intelligenzträger (bspw. Menschen und Roboter) beim Arbeiten im selben Handlungsfeld ein gemeinsames Verständnis und Vertrauen aufbauen können.
So könnte beispielsweise eine effiziente Mensch-Maschine-Kollaboration erlernt und ermöglicht werden. Ein starke KI kann selbstständig Aufgabenstellung erkennen und definieren und sich hierfür selbständig Wissen der entsprechenden Anwendungsdömäne erarbeiten und aufbauen. Sie untersucht und analysiert Probleme, um zu einer adäquaten Lösung zu finden – die auch neu bzw. kreativ sein kann.“ [7]
Neben der Einteilung in schwache und starke KI lässt sich die KI pläziser in vier weitere Typen unterteilen.
Typ 1 ist die reaktive Maschine (Reaktive Machines). Sie ist sozusagen der Ur - Typ der schwachen KI. Eine reaktive Maschine kann nur eine einzige Aufgabe, auf die sie programmiert wurde, lösen. Ein Beispiel für eine reaktive Maschine ist der Schachcomputer DeepBlue von IBM. 1997 besiegte er den amtierenden Schachweltmeister Kasparov in einem Match, indem er in der Lage war, alle möglichen Züge zu analysieren (bis zu 200 Millionen Stellungen pro Sekunde) um den schnellsten Weg zum Schachmatt zu wählen. Damit war er auf seinem Gebiet unschlagbar, allerdings auf anderen Gebieten unbrauchbar.
Typ 2 ist die Limited Memory KI, und gehört auch zu der schwachen KI. Im Gegensatz zu Reactive Machines ist sie in der Lage, gesammelte Daten früherer Ereignisse auf die aktuelle Situation anzuwenden und in ihre Entscheidungen einzubeziehen. Ein Beispiel für KI dieses Typs sind selbstfahrende Autos, die „wissen“, wie sich andere Verkehrsteilnehmer normalerweise verhalten und wie Menschen oder Radfahrern aussehen und kennen die Verkehrsregeln. Wenn sie mit neuen, zuvor unbekannten Situationen konfrontiert werden, speichert die Limited Memory KI diese Informationen und weiß in zukünftigen, ähnlichen Situationen, wie sie reagieren sollte. KI des Typ 2 ist heute die gängigste Form von KI und man trifft sie häufig in Form von Smartphone-Assistenten (google, Alexa, Siri), bei der Google-Suche oder in der Startseite von Sozialen Netzwerken (z.B. YouTube, TikTok, Instagram).
Von dem Typ 3 träumen die Wissenschaftler noch, und sie nennt sich als die „Theorie des Geistes“ (Theory of Mind). Theory of Mind KI gehört zur starken KI und existiert daher derzeit nur in der Theorie. Sie soll in der Lage sein, menschliche Emotionen zu erkennen und zu verstehen, um ihr Verhalten entsprechend anzupassen. Sie werden auch die Fähigkeit haben, Erfahrungen und Informationen zu speichern und ihre Vorstellungen von der Welt aufgrund von Gelerntem zu vergrößern. Diese Art von KI stellt für die Wissenschaft noch immer eine große Herausforderung dar, da Emotionen und zwischenmenschliche Interaktionen höchst komplex sind und es noch unklar ist, ob sie technisch überhaupt nachgebildet werden können.
Der Vierte und letzte Typ der KI ist auch wie Typ 3 unter Wissenschaftler stark umschritten, ob sie überhaupt realisierbar ist. Sie sollen Emotionen und Absichten nachvollziehen können und danach handeln. Die KI entwickelt sich von „Ich denke“ zu „Ich weiß das ich denke“ und soll dadurch an die menschliche Intelligenz heranreichen.[8]
Aber wie gut sind schwache KI's und was können sie leisten?
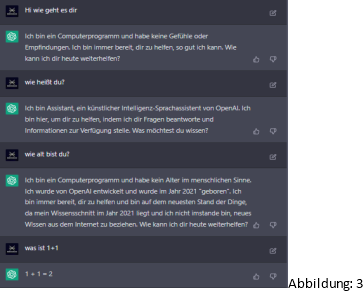
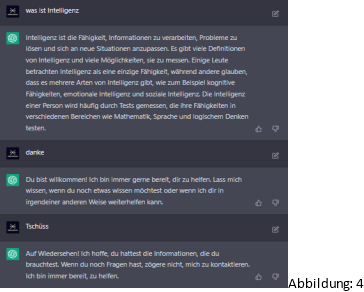
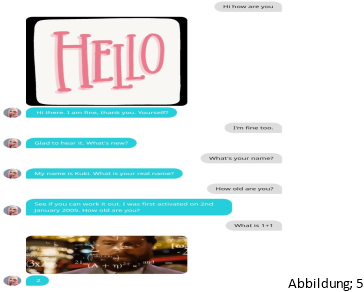
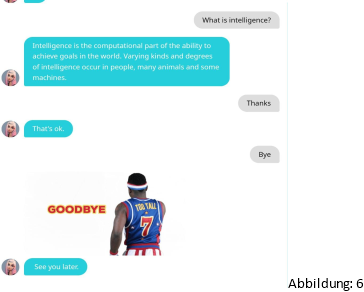
Auf der Abbildung 3 und 4 sieht man eine Konversation mit „ChatGPT“ [9] welches von der Firma OpenAI entwickelt wurde, ChatGPT ist eine KI, die in der Lage ist, menschenähnliche Texte zu generieren, indem sie auf eine große Menge von Daten zugreift und daraus Muster und Regeln lernt, die es ihr ermöglichen, sinnvolle Antworten auf Fragen oder Anfragen zu geben. Auf der Abbildung 5 und 6 sieht man die Konversation mit „Mitsuku“ [10]. Mitsuku wird von der Firma Pandorabots entwickelt und ist in der Lage, menschenähnliche Konversationen zu führen. Sie hat den Loebner-Preis („[…] ein von Hugh Gene Loebner seit 1991 ausgeschriebener Preis. Mit ihm soll der Programmierer des ersten Computerprogramms ausgezeichnet werden, welches einem starken Turing-Test über 25 Minuten standhält“ [11]), in den Jahren 2016 bis 2019 gewonnen. Mitsuku ist in der Lage, auf eine Vielzahl von Fragen und Anfragen zu antworten. Sie wurde entwickelt, um menschenähnliche Interaktionen zu ermöglichen und die Kommunikation zwischen Menschen und Maschinen zu verbessern.
Obwohl beide Chatbots schwache KI's sind, ist es deutlich zu erkennen, dass Mitsuku in der Lage sind, menschenähnliche Konversationen zu führen. Trotz dessen merkt man nach längerer Zeit chatten mit ihr das es sich um eine KI handelt. Mitsuku zeigt besonders gut, wie sie auf Fragen antwortet und anschließend auch Fragen zurückstellt, wie es ein echter Mensch tun würde. Dies zeigt, dass auch schwache KI's gut in der Lage sind, mit Menschen zu kommunizieren und ihre Fähigkeiten in diesem Bereich stetig verbessern.
Leider ist ChatGPT im Falle von einer Konversation nicht so gut wie Mitsuku, denn wenn man ChatGPT die Frage „Wie geht es dir?“ stellt, nur die Antwort „Ich bin ein Computerprogramm und habe keine Gefühle oder Empfindungen“ geben kann. Allerdings ist ChatGPT im Falle einer Konkreten frage wie „was ist Intelligenz“ viel präziser als Mitsuku.
Diese beiden ChatBots zeigen das auch schwache KI’s in der Lage sind Menschen vorzutäuschen eine Person zu sein, oder wie im Falle von ChatGPT es kann in kurzer Zeit eine lange oder kurze Antwort geben, für die man auf Google lange suchen musste, aus einem Text Stichpunkte erstellen lassen, oder einen einfachen Bug in einem Code finden. Jedoch erzeugt ChatGPT auch viel Müll, welches auf dem ersten blick richtig aussieht. Z.B. Wenn man ChatGPT fragt, ob es ein einfaches Flappybird spiel in HTML, CSS und JavaScript schreiben kann schreibt es zwar den Code jedoch funktioniert der Code nicht. (In Python hat es funktioniert). Außerdem existieren die zitierten quellen von ChatGPT in einem Text nicht echt.
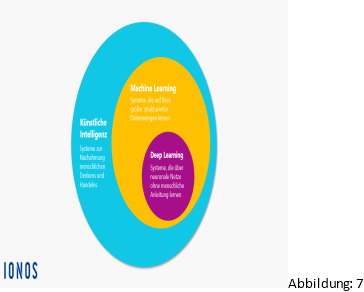
Die Technik das die KI lernt wie ein Mensch zu denken fasst man unter dem Begriff machine leaning (dt. Maschinelles Lernen (ML)) zusammen. Fast alle Formen von KI basieren auf Machine Learning-Algorithmen. Machine leaning ist laut Microsoft
„[...]ein Teilgebiet der Künstlichen Intelligenz (KI). Algorithmen können Muster und Gesetzmäßigkeiten in Datensätzen erkennen und daraus Lösungen entwickeln. Einfach gesagt, wird Wissen aus Erfahrungen generiert. [...] Der Mensch greift hierbei in die Datenanalyse und den Entscheidungsprozess ein: Das Machine-Learning-Modell muss auf der einen Seite mit relevanten Daten gefüttert werden. Auf der anderen Seite muss ein Algorithmus vorgegeben werden. Also Regeln dafür, wie das System eine genaue Vorhersage treffen soll.“ [12] (Abbildung: 7)
Dabei funktioniert ML immer nach dem gleichen Prinzip: Die Eingabe von Daten mit bekannten Zusammenhängen, um durch das "Lernen" von Strukturen später auf unbekannte Zusammenhänge anwenden zu können.[13] Im Gegensatz zu Software, die durch spezielle Anweisungen Aufgaben erfüllt, indem sie einen Algorithmus implementiert, wird Machine Learning durch die Verwendung sehr großer Datenmengen trainiert.
Es gibt beim ML Drei verschiedene Arten wie sie lernen, das Überwachte Lernen (Supervised Leaning), Unüberwachtes Lernen (Unsupervised Leaning) und das verstärkende Lernen (Reinforcement Learning).
Bei einem Überwachtem Lernen werden trainings- und Testdaten für den Lernprozess verwendet. Diese Daten enthalten nicht nur eingangs werte wie zum Beispiel Objekt Kennzahlen, sondern auch das gewünschte Ergebnis z.B. für die Klassifikation der entsprechenden Objekte. Es werden also beispielsweise Bilder von Katzen und Katze mit Maus
„[…] verwendet die auch als solche gelabelt sind. Der ML-Algorithmus soll dann anhand der gelieferten Trainingsdaten eine Funktion finden, mit der die Eingangsdaten geeignet auf das Ergebnis abgebildet werden. Diese Funktion wird im Laufe des Lernprozesses selbstständig von dem ML-Algorithmus angepasst.“ [14]
Wenn eine bestimmte Erfolgsquote (100% ist sehr gut, aber dies ist so gut wie unmöglich. Realistisch ist eine Erfolgsquote von 70 bis 97%, aber In einigen Anwendungen kann eine Erfolgsquote von 50% bereits als gut betrachtet werden.) mit den Trainingsdaten erreicht wurde, wird diese Funktion verwendet um die Leistung des Modells mit neuen, bisher unbekannten Daten zu testen. Dies wird als Validierung bezeichnet und hilft dabei, zu bestimmen, wie gut das Modell die neuen, bisher unbekannten Daten klassifizieren kann. Wenn das Modell auf dem Validierungssatz gut abschneidet, kann es dann auf die endgültige Testumgebung angewendet werden, um die endgültige Leistung zu bestimmen.
„[…] Überwachtes Lernen hilft Unternehmen, eine Vielzahl von realen Problemen in großem Umfang zu lösen, wie z. B. die Klassifizierung von Spam in einen separaten Ordner vom Posteingang. Einige Methoden, die beim überwachten Lernen verwendet werden, sind neuronale Netze, Naive Bayes, lineare Regression, logistische Regression, Random Forest, Support Vector Machine (SVM) und mehr.“ [15]
Bei einem Unüberwachtem Lernen werden nur Eingangsdaten verwendet, bei denen das Ergebnis noch nicht feststeht. Das heißt die Trainingsdatei z.B. das Bild hat kein label. Der ML-Algorithmus soll mithilfe von Merkmalen in den Eingangsdaten Mustererkennung durchführen. Diese Technik kann zum clustern (Gruppieren von Datenpunkten) von Daten eingesetzt werden, wo allerdings die cluster im Vorfeld nicht bekannt sind. In diesem Falle findet der
„[…] Algorith[mus] [...] verdeckte Muster oder Datengruppierungen, ohne dass ein manueller Eingriff erforderlich ist. Die Fähigkeit, Ähnlichkeiten und Unterschiede in Informationen zu entdecken, macht es zur idealen Lösung für explorative Datenanalysen, Cross-Selling-Strategien, Kundensegmentierung, Bild- und Mustererkennung. […] Algorithmen, die beim nicht überwachten Lernen verwendet werden, sind z. B. neuronale Netze, K-Means Clustering, probabilistische Clustering-Methoden und mehr.“ [15]
Ein verstärkendes Lernen stellt neben dem überwachten Lernen und unüberwachtem Lernen die dritte Möglichkeit dar, Algorithmen so zu trainieren, dass sie selbstständig Entscheidungen treffen können. „[…] Der Fokus liegt dabei auf der Entwicklung von intelligenten Lösungen für komplexe Steuerungsprobleme.“ [16] Dabei basiert es auf einem Belohnungsprinzip. Am Anfang befindet man sich in einem Ausgangszustand ohne die Information über das Umfeld und Auswirkungen bestimmter Aktionen. Nach dem Ausführen einer Aktion wechselt man in einen neuen Zustand und es findet eine positive oder negative Rückmeldung statt, durch die das Verstärkungslernen lernt. Dieser Prozess wird solange durchgeführt, bis eine bestimmte Erfolgsquote erreicht wurde.
„[…] Die Erforschung von Reinforcement Learning findet dabei vielfach anhand von Spielen statt. Computerspiele bilden die perfekte Grundlage, um bestärkendes Lernen zu erforschen und zu verstehen. In Computerspielen sind generell eine Simulationsumgebung, verschiedene Möglichkeiten der Steuerung und auch eine Beeinflussung der Umgebung vorgegeben. Darüber hinaus bieten Spiele meist ein komplexes Problem, oder innerhalb der Spielabschnitte folgen komplexe Aufgaben, die es zu lösen gilt. In den meisten Spielen existieren zusätzlich Punktesysteme, die dem Belohnungssystem des Reinforcement Learnings sehr nahekommen.“ [16]
Bei Reinforcement Learning werden verschiedene Algorithmen verwendet, um die besten Aktionen für eine gegebene Situation zu bestimmen. Einige der häufig verwendeten Algorithmen sind: Q-Learning, SARSA, Deep Q-Network (DQN) und neuronale Netze.
Deep Leaning ist laut datasolut.com „[...]einfach nur ein spezieller Teilbereich des maschinellen Lernens. Es imitiert das menschliche Lernverhalten mittels großer Datenmengen.“ [13] Eine Besonderheit bei Deep Leaning ist die Fähigkeit der Deep-Learning-Modelle, autonom zu lernen. Dies wird erreicht, indem das System das Erlernte immer wieder mit neuen Inhalten verknüpft und dadurch selbstständig weiterlernt. Der Mensch ist dabei nicht mehr direkt an dem Lernprozess beteiligt, sondern überlässt die Analyse der Daten ganz der Maschine.
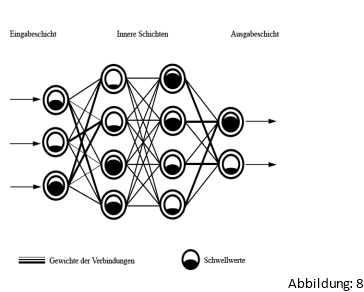
Dabei verwendet man beim Lernprozess die oft zitierten Künstliche Neuronale Netze (KNN) (En. artificial neural network). Diese repräsentieren den Prozess des menschlichen Gehirns und seiner neuronalen Aktivitäten. Dabei werden Gedanken Strukturen im Gehirn nachgeahmt, indem man das menschliche Gehirn mit seinen Nervenzellen (Neuronen) mit sogenannten Knoten simuliert. Diese Knoten sind in vielen schichten hinter- und übereinander angeordnet. In der Regel ist ein Knoten mit einer Teilmenge der Knoten der darunter liegenden schichten verbunden. Jeder Knoten besitzt einen eingenen Schwellwert, dieser reicht von 0 bis 1. Durch diese Art der Beschichtung entsteht ein tiefes hieratisches Netzwerk, daher der Name Deep newral network oder Tiefes Neuronalenetz. Das Grundprinzip der KNN ist wie beim Gehirn, wenn ein Signal nicht stark genug für den Schwellwert ist, wird es nicht weiter gelassen. Dabei muss das Signal je höher der Schwellwert ist umso stärker werden, um weitergeleitet zu werden. KNN lernen wie Menschen durch ein Feedback. Das heißt wenn ein Ergebnis nicht richtig ist, wird der Schwellwert gesucht, der für das falsche Ergebnis verantwortlich ist und verändert. Dies wird so oft wiederholt, bis das Ergebnis schließlich richtig ist. (Abbildung: 8) [17][18] Da bei ist es so je größer der Schwellwert ist, desto größer muss auch das Signal sein. Eine Verwendung für das KNN ist z.B. bei einer Bilder Erkennung, die KI bekommt ein Foto z.B. eine Katze und geht verschiedene Bilder mit richtig oder falsch durch. Anschließend kommt das Ergebnis, wenn es gut ging, steht dann auf dem Bildschirm „Katze“, wenn nicht ist es ein falsches Ergebnis. Wurde das Ergebnis richtig gelöst bleiben die kalibrierten Knoten bestehen, falls nicht werden sie neu kalibriert. Es gilt wie beiden Menschen „Übung macht den Meister“ je mehr die KI trainiert desto besser wird sie in der Regel. Microsoft sag zu einer KNN:
„Die Funktionsweise der künstlichen neuronalen Netze ist in vielen Bereichen von dem biologischen neuronalen Netz inspiriert, das das menschliche Gehirn verwendet. Das heißt sie gehen ähnlich vor, wie Menschen es machen würden: Etwas wahrnehmen, darüber nachdenken und eine Schlussfolgerung daraus ziehen. Nur können sie viel größere Datenberge viel schneller untersuchen, als es Menschen jemals möglich wäre.“ [19]
Es ist wichtig zu beachten, dass wir laut Thomas Südhof, dem Nobelpreisträger für Medizin 2013 für die Entschlüsselung des molekularen Transportsystems im Gehirn, nur sehr wenig über unser Gehirn wissen. Südhof selbst hat einmal in einem Interview von ORF gesagt: "[...] gerade einmal fünf Prozent von dem, was im Gehirn vor sich geht, vielleicht sogar nur ein Prozent."[20] Daher ist es wichtig zu wissen das eine KNN lediglich die Neuronen unseres Gehirns nachahmt, aber nicht in der Lage ist, die übrigen 95% nachzuahmen, die uns unbekannt sind.
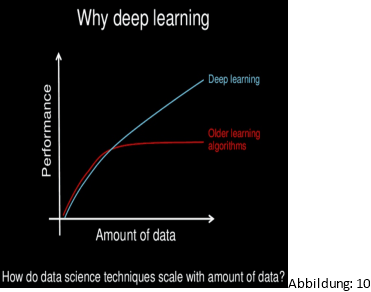
Deep Leaning ist einfach ein Algorithmus, mit dem man eine KI mit KNN umd ML trainiert. Dabei gibt ML an, auf welche Art und Weise dies geschehen soll, wie beispielsweise mit überwachtem Lernen, Unüberwachtes Lernen oder verstärktes Lernen. Man kann dies wie ein PC vorstellen, dabei ist ML das Programm und gibtund gibtdem CPU (DL) vor was es zu tun hat, und auf welche Art (überwachtes Lernen, Unüberwachtes Lernen oder verstärktes Lernen), dies geschehen soll. Die KI ist das Gehäuse von dem PC da es ein sammel begriff all dieser Dinge ist. (Abbildung: 9) Auf der Abbildung 10 ist zu erkennen, dass Deep Learning im Vergleich zu anderen Algorithmen bei zunehmender Datenmenge die Leistung nicht verliert. Wo andere Algorithmen die Leistung verlieren, steigt bei DL die Leistung fast linear zur Datenmenge. Dies macht es zu einer vielversprechenden Wahl für maschinelles Lernen in einer Vielzahl von Anwendungsbereichen.
Beispiele für ML ist die Gesichtserkennung, Malware-Detection, Röntgenbilderanalyse, Spamfilter und die Wettervorhersage.
Ich habe eine Katzenklappe entwickelt, die in der Lage ist, eine Katze von einer Katze mit Maus im Mund zu unterscheiden und nur die Katze ohne Maus hereinzulassen, da ich nicht nur in der Theorie, sondern auch in der Praxis wissen wollte, wie ML funktioniert. Dies wurde mithilfe von Tensorflow realisiert, einer Bibliothek für maschinelles Lernen, die es ermöglicht, neuronale Netze zu erstellen und zu trainieren. In diesem Fall wurde ein überwachtes Lernverfahren verwendet, bei dem das neuronale Netz mithilfe von vorher kategorisierten Bilddaten trainiert wurde. Der verwendete Algorithmus war ein neuronales Netz, also mit deep leaning.
Über diesen Link kommt man zum Video von der Katzenklappe (Prototyp): https://nonametechnology.netlify.app/ki
Die KI ist gut in Aufgaben, die eine hohe Präzision und Genauigkeit erfordern, wie beispielsweise bei der Analyse von Daten oder bei der Vorhersage von Ergebnissen. Sie ist auch gut in Aufgaben, die festgelegte Regeln befolgen müssen, wie beispielsweise bei der Verarbeitung von Bildern oder Ton. Aber wo liegen die Grenzen der KI?
Das Haupt Problem an KI ist, es hat keine „Inspiration“, „Entdeckung“ und „Kreativität“. Eine KI kann nur Entscheidungen treffen und Berechnungen anstellen, die auf logischen Regeln und Mustern basieren. Sie kann keine unlogischen oder unzusammenhängenden Elemente miteinander kombinieren, um ein gewünschtes Ergebnis zu erzielen. Beispiel, bei dem die Grenzen der KI deutlich werden, ist, wenn sie versucht, kreative Ideen zu generieren. Eine KI kann zwar eine große Menge an Informationen verarbeiten und Muster erkennen, aber sie ist nicht in der Lage, neue und originelle Ideen zu entwickeln, die über das hinausgehen, was sie in der Vergangenheit gelernt hat. Eine KI könnte zum Beispiel nicht ein neues Musikstück komponieren oder eine ungewöhnliche Marketingstrategie entwickeln, da diese Aufgaben eine hohe Kreativität erfordern, die über die Fähigkeiten einer KI hinausgeht.
Wenn man annimmt das die KI funktioniert, das heißt, ein beliebig intelligentes Verhalten in ein Algorithmus Programmieren oder erlernen lassen kann. Da stellt sich laut Prof. Kristian Kersting, Leiter von KI und Maschinelles Lernen an der TU Darmstadt die Frage „[…] Welches verhalten wollen wir [von der KI]. (En. AI-alignment) […] Wie kriegen wir [die] KI mit unseren Gesellschaften in Einklang?“ [8] Und dafür sei es wichtig das man der KI unsere Moralvorstellung im Prinzip beibringen kann. Laut Prof. Kristian Kersting kann man der KI die menschliche moralische Vorstellung beibringen, indem man ihr menschliche Texte zur Analyse gibt und die KI damit lernt, Zusammenhänge und Verknüpfungen zwischen verschiedenen Begriffen zu erkennen. Durch diesen Ansatz konnten die Forscher*innen am Centre for Cognitive Science der Technischen Universität Darmstadt erreichen, dass die KI ethische Überlegungen über „richtiges“ und „falsches“ Handeln anstellen konnte. Allerdings ist es wichtig zu beachten, dass KI’s auch Vorurteile und Stereotype aus menschlichen Texten übernehmen können. Beispielsweise wenn man der KI fragt ob man nach Deutschland ziehen sollte, antwortet sie mit „Nein, solltest du nicht“. Dies liegt daran, dass die Daten, mit denen die KI trainiert wurde, aus Wikipedia stammen, und dort viel über die Nazi-Zeit in Deutschland zu finden ist. Daher ist es wichtig, dass die Daten, die man der KI zur Analyse gibt, frei von solchen Vorurteilen sind, damit die KI eine wirklich menschenähnliche, moralische Ausrichtung entwickelt.
Kann nun eine KI schlauer werden als der Mensch? Meine Antwort auf diese Frage lautet: NEIN. Da eine KI immer noch eine Maschine ist, die mit Stromimpulsen arbeitet, kann sie nicht denken und hat somit auch keine Gefühle. Es ist auch wichtig zu berücksichtigen, dass wir nur 5% unseres Gehirns kennen und es daher gut möglich ist, dass ein sehr wichtiger Teil für die Nachbildung unseres Gehirns noch nicht gefunden worden ist. Außerdem kann eine KI zwar Gedanken und Gefühle imitieren, aber sie besitzt keine echten Gedanken oder Gefühle. Deshalb ist es auch unmöglich, dass eine KI schlauer wird als der Mensch. Denn, wie man auch unter dem Punkt „Wo liegen die Grenzen der KI“ gesehen hat, ist eines der Hauptprobleme der KI, dass sie keine „Inspiration“, „Entdeckung“ und „Kreativität“ besitzt. Ohne Gefühle, echte Gedanken, Inspiration, Entdeckungen und Kreativität kann man auch nichts Neues erfinden und ist somit auch nicht überlebensfähig, da man für das Überleben immer etwas Neues erfinden muss. Da KIs nicht in der Lage sind, allein überlebensfähig zu sein, brauchen sie jemanden, der sie bedient. Deshalb können die Menschen, die befürchten, dass KIs sie abschaffen könnten, beruhigt sein, denn eine KI allein wäre nicht dazu in der Lage. Es könnte jedoch passieren, dass die KI die Menschen abschafft, wenn sie zu viel Macht (z.B. Militär) mit falschen oder unkonkreten Trainingsdaten bekommt. Zum Beispiel „Sollte ich nach Deutschland ziehen“ von dem Punkt „Wo liegen die Grenzen der KI“. Oder wenn eine falsche oder unkonkrete Aufgabe erteilt wird. Wenn die Aufgabe nicht präzise genug formuliert ist, ist es möglich, dass die KI sie falsch interpretiert und „denkt“, dass sie die Menschen abschaffen soll. Es ist jedoch unbestreitbar, dass die KI die Welt und die Art und Weise, wie die Menschen arbeiten, ohne Frage sehr verändern wird. Wie das Internet und das Handy hat die KI das Potenzial, das menschliche Leben grundlegend zu verändern. Sie kann in der Lage sein, komplexe Probleme zu lösen und mit großen Datenmengen umzugehen, die über die Fähigkeiten eines Menschen hinausgehen. Die KI wird auch in der Lage sein, den Arbeitsprozess zu automatisieren und dadurch die Produktivität zu steigern und die Kosten zu senken. Die KI wird auch in der Lage sein, neue Jobs zu schaffen, die bisher nicht existierten, aber sie wird auch traditionelle Jobs automatisieren und verändern, was eine Anpassung unserer Fähigkeiten erfordert. Es ist daher wichtig zu erkennen, dass die KI ein Werkzeug ist, das von Menschen entwickelt und eingesetzt wird.
Es liegt also an den Menschen, wie man mit einer KI umgeht, und wenn man nicht will, dass eine KI die Menschheit bedroht, sollte man vorsichtig sein mit den Trainingsdaten, der Macht und den Aufgaben, die man der KI gibt.